AI in Construction: LLMs and Math
Large Language Models are not great at math. They’re sometimes wrong. They’re always slow and expensive.
Collin Tsui
11/4/20254 min read


AI dominates today’s business headlines, with many articles talking about Tech, Finance, Software… computer centric industries. But what about Construction? We’ll explore each of these topics from a Construction perspective over a few blog posts.
Hordes of vendors line up to sell you AI-powered solutions. The first question I ask is which type of AI, because AI can have many flavors:
Machine Learning (ML)
Large Language Model (LLM)
Agentic AI
This post further explores Large Language Models, as part of a series on AI in Construction.
My last post talked about how LLMs are non-deterministic – identical input into the same LLM will yield different responses every time. That is a feature, not a bug – unless what you’re asking only has one right answer. Like math.
I thought I would explore this a little bit more. Using openrouter.ai, I tested the two recent LLMs from each of the four premier AI companies:
OpenAI GPT-5
OpenAI GPT-5 Chat
Google Gemini 2.5 Pro
Google Gemini 2.5 Flash
Anthropic Claude Opus 4.1
Anthropic Claude Sonnet 4.5
xAI Grok 4
xAI Grok 4 Fast
Round 1: Basic Arithmetic
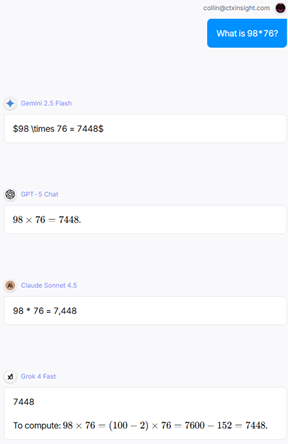
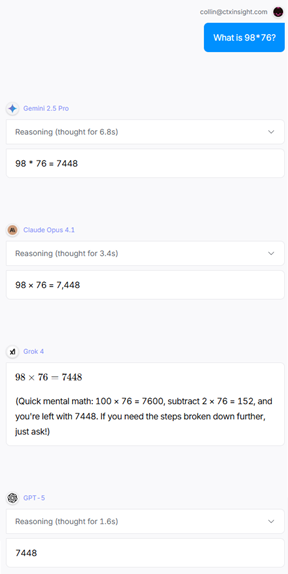
The first question is 5th grade arithmetic - two-digit multiplication:
98 x 76 = 7448
All eight LLMs got it right. And Gemini 2.5 Flash apparently wants to become an accountant.
Round 2: Multi-Step
Next, I added a step, and used three-digit numbers:
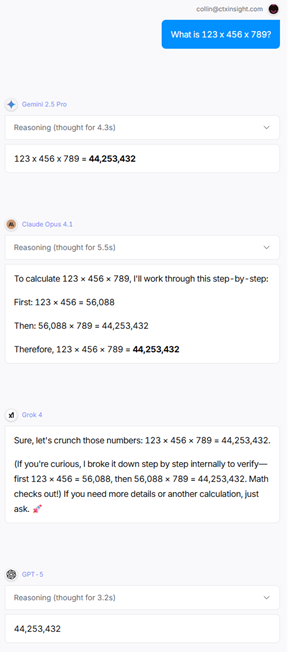
123 x 456 x 789 = 44,253,432
Gemini 2.5 Flash and GPT-5 Chat got it wrong. Generally speaking, the LLMs that add “Reasoning” do better as complexity increases. Reasoning is when an LLM “talks to itself”, generating the text of a multi-step plan, then essentially considering that new text as if it were instructions in the prompt.
So, two got it wrong, and the other six did okay. I think Grok was after some bonus points with that emoji… to the moon!



Round 3: Order of Operations
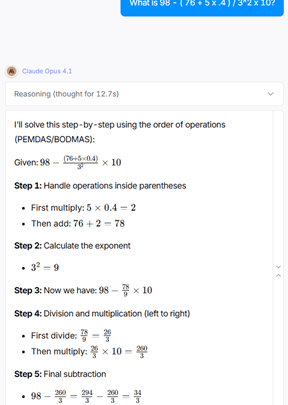
Now on to middle school math. Let’s see which LLM knows BEDMAS:
98 - ( 76 + 5 x .4 ) / 3^2 x 10
= 98 - 78 / 9 * 10
= 11.333
All eight LLMs got this one right, despite it being harder than the last round. This is commonly referred to as the jagged frontier – LLMs are dazzlingly brilliant with some very hard problems, but incredibly stupid with seemingly easy ones. It’s impossible to know which you’re getting. Be wary – the jagged frontier is real.
Anyhoo, the screenshots run a little long, so I’ll just show some highlights.
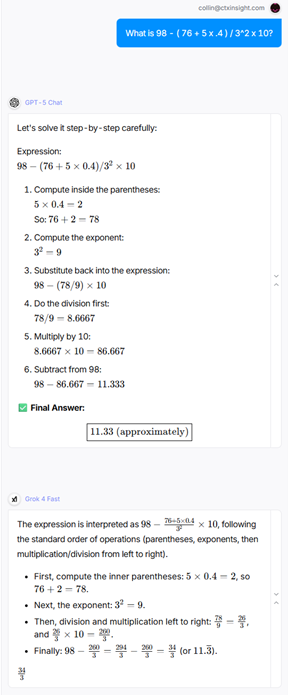


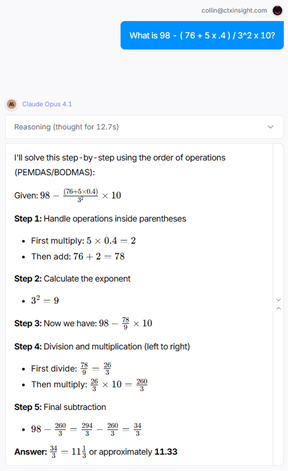
It’s less exciting when everyone’s right, I know. This is like bumper cars where no one hits each other. Sooo… let me be the jerk here.
Processing Time
Take a look at those results again. Notice the timing on the reasoning models: 16.4s for Gemini 2.5 Pro and 12.7s for Claude Opus 4.1… for one calculation. That is much faster than me, but much slower than Excel. (I’m glad I’m not the benchmark!)
Now put that in the context of a finance dashboard, where the sample problem is about as complex as metrics like YOYTD or CAGR (Year Over Year-To-Date, or Compound Annual Growth Rate). I might have half a dozen such metrics in a high-level dashboard, or hundreds such lines items in a detailed report, and Power BI page would need to load in under 1-3 seconds (before users think its broken). It would take over a minute with LLMs.
When it comes to math, Excel and Power BI’s Vertipaq engine are highly optimized for speed and efficiency. LLMs are simply one to two orders of magnitude too slow, at least when compared to existing tools.
Cost
Processing time doesn’t come free, so let’s look at that, too. Openrouter tracks the cost for each prompt/response. Here are the estimated costs for the two LLMs, each computing just the last sample question:
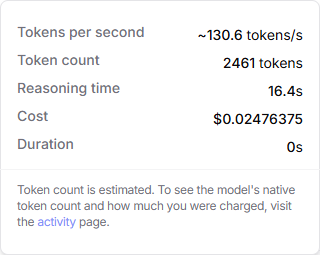
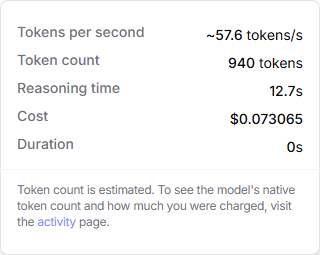
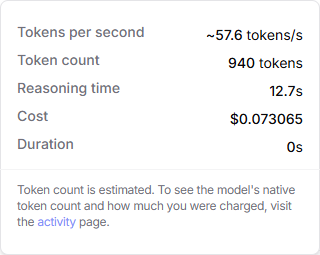
Google Gemini 2.5 Pro
Anthropic Claude Opus 4.1
2.5¢ and 7.3¢ doesn’t look so bad. But consider a cost report that contains a hundred line items with a YOYTD metric, used by a dozen employees one per weekday. That could mean compute costs of $7,000 - $21,000 over a year for that one report alone ( $0.073 x 100 x 12 x 250 = $21,900 ).
Versus $2,000 per year for 12 Pro licenses with unlimited Power BI use, LLMs are simply uneconomical for mass data processing.
(I know there’s Power BI CoPilot, Agentic AI, and MCPs… we’ll get there soon, just give me a couple more posts to finish this exploration first).
Ready for analytics you can afford?
Are you having success with AI on words, but struggling to do the same with project data? Need to get reliable metrics to your team on a budget? Let's talk!
I build custom Power BI solutions that transform raw data into quick metrics to keep projects on time and on budget. Contact me today to make your data clear.